
Patricia Johnson, PhD, assistant professor of radiology at NYU Langone Health, is the lead author of a study titled “Deep Learning Reconstruction Enables Prospectively Accelerated Clinical Knee MRI,” published on January 17 in the journal Radiology. The authors have found that knee images acquired at fourfold acceleration and reconstructed with a deep learning algorithm are diagnostically equivalent to those obtained with clinical MRI at twofold acceleration. The images generated with the deep learning protocol, which is twice as fast as conventional compressed sensing MRI and four times as fast as traditional fully sampled MRI, matched clinical images in diagnostic content and outranked them on perceived quality.
The study is part of fastMRI, a collaboration between the Center for Advanced Imaging Innovation and Research and Meta AI Research (formerly Facebook AI Research) with the ultimate goal of making MRI up to 10 times faster. The initiative has also produced the largest open set of curated, anonymized raw MRI data for machine learning research on image reconstruction and promoted innovation in the field by holding open reconstruction competitions in 2019 and 2020.
Before joining NYU Langone faculty, Dr. Johnson was a postdoctoral fellow at NYU Grossman School of Medicine. She holds a doctorate in medical biophysics from University of Western Ontario, where her research focused on motion correction in MRI. Our conversation was edited for clarity and concision.
How did you find your way to postdoctoral training at NYU Langone?
I saw a postdoc opening with Florian Knoll and thought it would be a good fit. I was already familiar with a lot of his work at that point. I reached out to him and we met at the 2018 meeting of the International Society for Magnetic Resonance in Medicine in Paris. We had coffee and talked about research and the projects he had ongoing, and that was it—I joined NYU in early 2019.
At the time, Florian Knoll and colleagues were developing a new type of MRI reconstruction based on machine learning. What attracted your attention to their research?
As a PhD candidate, I was working on motion correction for neuroimaging and was focused on acquisition strategies like motion navigators. About midway through my PhD, deep learning in imaging was starting to become a thing and it became apparent that deep learning image processing techniques could be really promising for motion correction. So I pursued that angle towards the end of my PhD.
I was also interested in deep learning for image reconstruction, which is what Florian was doing. It was related to what I was working on but different enough that it seemed exciting and new.
And right away, you became involved in the fastMRI collaboration—tell me a little about that project.
When I started my postdoc, that was roughly around the time we started collaborating with Facebook AI Research (now Meta AI Research). It was a very collaborative effort in terms of developing the deep learning model for image reconstruction. We had our own models at that point and they worked well. But Meta AI had expertise in larger models and more compute resources—experience that helped take what we had developed and bring it to the next level. It’s been a really strong partnership, led on NYU Langone’s side by Florian Knoll and Michael Recht and Daniel Sodickson. It has helped us improve our reconstruction models, open them up to the public with our open source GitHub repository, and build them to be more robust and generalizable.
Your most recent study adds to the case that fourfold acceleration with deep learning has the potential for clinical use. How do you think about what this work demonstrates and how it fits with the broader goal of making MRI up to 10 times faster?
Right now we’re doing fourfold acceleration and we’re generating images that are essentially indistinguishable from the clinical images.
We could accelerate these images tenfold but they would not look as good—that’s just the reality of it. But for some applications like screening, or potentially even applications where you don’t have human readers, where you have computer-aided diagnostics, tenfold might be completely achievable.
In musculoskeletal imaging of the knee, if a human reader is trying to diagnose a small meniscal tear, I don’t think an acceleration factor of 10 is feasible—there’s just not enough data there. But for certain applications like screening or where abnormalities are larger or with computer-aided diagnostic tools—that’s a regime of tenfold acceleration that I can see being practical.
In this study, the deep learning reconstruction is done prospectively, meaning that the accelerated MRI scan is tailored to that reconstruction from the start. In a 2020 study, the team showed similar interchangeability but with retrospective acceleration done by subtracting data from fully sampled scans. Why is the new, prospective study significant and what does it add to the body of evidence about deep learning reconstruction?
I think it helps build confidence in the technology. We scanned the subjects with the clinical protocol and then we scanned them with the fast protocol—and can show that the two are clinically interchangeable. That builds confidence that we can implement our method prospectively rather than just using a clinical protocol and removing data.
We can also get better image quality a lot of the time from the deep learning accelerated acquisition rather than from full acquisition with retrospectively removed data, just because the exam is shorter and there’s less likely to be patient motion. Being able to show better quality with a shorter exam and interchangeability in terms of diagnostics brings this technology closer to clinical translation.
Has the team been surprised by any findings or any developments in the course of this study?
I think there were no surprises. We did expect the method to perform well both retrospectively and prospectively.
One interesting thing in this project—both in the retrospective and prospective studies—is that we’re actually adding a bit of noise to the images. Deep learning has a denoising effect that makes the images look a little smoother than radiologists are used to. Initially, there was a little bit of pushback that the images looked oversmooth. After we added just a little bit of adaptive noise, radiologists couldn’t even tell the deep learning reconstructions from conventional ones in a lot of cases.
This is more about the aesthetics of radiologic images, more about the visual preferences of radiologists than about the actual information content of the image—is that right?
Yes, and I think there’s also a little bit of reader confidence involved. If radiologists are seeing an image that looks very much like they’re used to, they’re confident in the information content of that image. But if the image appears oversmooth, they’re worried that there might be potentially details missing, so it’s about more than just aesthetics.
In the literature, this kind of image reconstruction is sometimes referred to as image generation, but this is very different from the type of generative AI that has been recently making headlines and going around the internet playground. Can you talk about the fundamental differences between the models that you’re developing and the principles behind generative AI such as DALL•E-2 or ChatGPT?
Yes, that’s an important distinction. It’s important to know that the images we reconstruct are not synthetic.
Deep learning image reconstruction is really an extension of what we’ve been doing with iterative image reconstruction for a very long time. It’s an extension of compressed sensing but our regularizer is learned from training data as opposed to using something like a sparsity constraint. In this deep learning image reconstruction process, consistency with the acquired data is enforced just like it would be for conventional compressed sensing, and then you’re using prior information to solve the ill-posed inverse problem and reconstruct an image.
The model really learns how to separate undersampling artifacts from true image content, and it does that by being given a lot of examples of artifacted images and their corresponding ground truth image. My interpretation of it is that the model learns the structure and the content of the training images and what is real image information and what is an artifact.
Things need to be well represented in that training set for the reconstruction to work properly—that means different kinds of pathologies and anatomical variability. Things that aren’t well represented in our training set, the reconstruction probably won’t work so well for those. For example, we didn’t have any cases where there was metal in the knee, so it’s likely that this model may not perform so well on such cases and that the traditional reconstruction techniques would probably be the best approach there.
How do you see the path for taking this kind of reconstruction from the realm of research to an actual clinical application?
I think it’s well on the way to clinical application. Some vendors now have similar products that are FDA approved. I’m not aware of it being used in routine clinical imaging, but I think studies like ours may help in that regard—they may help make clinicians more aware of this and give them confidence that the technology does work well in the clinical setting.
As someone who has been working with deep learning image reconstruction for several years, where do you think your work and this research area are going?
If we can adopt this clinically and broadly, if all exams can be significantly shorter, it’s really going to improve accessibility, patient experience, and patient comfort.
My goal is to bring MRI to more patients, especially in places that don’t have as many MRI scanners as we do and where wait times can be really long. Improving scan time by a factor of two or four is going to have a huge impact in those patient populations.
What about the size of scanners, strength of magnets—do you see deep learning image reconstruction playing a role in relaxing some of the hardware constraints in MRI?
I surely think it’s possible, and there is a trend now towards lower field and a lot of interest in low field MRI. When you’re at low magnetic field you’re already starved for signal, so acceleration may not be the move to make, but denoising could be really beneficial there. And when you’re starting to have images that are lower visual quality than human readers are used to, that may be a point where deep learning, computer aided diagnostics, and AI classification tools could be really beneficial as well.
One aspect of the fastMRI collaboration is the sharing of resources with the broader imaging research community. The fastMRI dataset is already the largest curated collection of open MRI data. Does the team expect to be making further additions to this dataset? And what are some considerations associated with creating such a resource?
Yes, there are plans for that. Specifically, we’re hoping to release a prostate MRI dataset in the coming months.
All data has to be anonymized, and for the prostate dataset, we have radiologists assign labels for whether there is a lesion and if so, what grade it is. So there’s a fair bit of work involved in the labeling and the anonymization.
In the past, we released fully sampled image data of fairly straightforward T2 turbo spin echo sequences. People can take that data and work with it very easily—for a fully sampled reconstruction it’s just an inverse Fourier transform. The prostate data is not as simple to work with. We have a biparametric protocol, and this will be the first time we’re sharing raw diffusion imaging data. The standard reconstruction for that is a little more challenging, so we’re also working on providing reconstruction scripts that will make the data easier to handle for the community, and that has also been a significant effort.
You began working with deep learning as a graduate student and have been researching in this area ever since. What did originally arouse your interest in this technology?
At the time, it was a means to an end. I had a problem—motion in MRI—and it became clear that deep learning would be a good tool for solving that problem. I wasn’t particularly interested in the technology per se. Once I started working with deep learning for image processing, that spiraled into a more general exploration and excitement about other problems in imaging that we could solve with this tool.
What underlies your interest in MRI?
I’ve always been fascinated by medical imaging ever since I was little. At that point I was only aware of X-rays, but I though it was really cool that you could just take images of the body and see the bones. Later, MRI—when I started learning a little bit more about what it was, the mechanisms of how it works, the fact that there’s no ionizing radiation, and the really powerful soft tissue contrast, that’s kind of why I started in MRI research in my PhD.
Was there a specific experience you had in childhood that precipitated this fascination with medical images?
I was a gymnast when I was a kid, so I was always hurting myself. I did artistic gymnastics—vault, bars, beam, floor—from age 4 to 19. So, I frequently got X-rays of various parts of my body. Also, when I was 12 I came down with appendicitis and had a CT—although at the time I didn’t know that that’s what it was—and I remember getting those images and thinking they were so cool. I couldn’t tell what I was looking at, but the fascination was there.
Related Resource
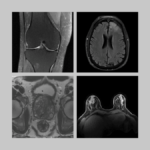
Raw k-space data and DICOM images from thousands of MRI scans of the knee, brain, and prostate, curated for machine learning research on image reconstruction.
Related Stories

The fastMRI dataset now includes curated breast MRI data to boost AI innovation in radial, dynamic contrast-enhanced, ultrafast MRI of the breast.

Radhika Tibrewala, graduate student in biomedical imaging, talks about the new fastMRI prostate dataset, deep learning in MRI, and how she started a PhD remotely in 2020.

Florian Knoll, incoming chair of imaging at University of Erlangen–Nuremberg, talks about his background, not being greedy, and why he does what he does.